Research topics ...
… that I'm interested in but don't have time to work on at the moment.
If you're looking for topics specifically related to Solid and data sovereignty look here.
If you're looking for some more topics related to semi-autonomous Web Agents look here and for early work on the topic see here.
Suitable Representations
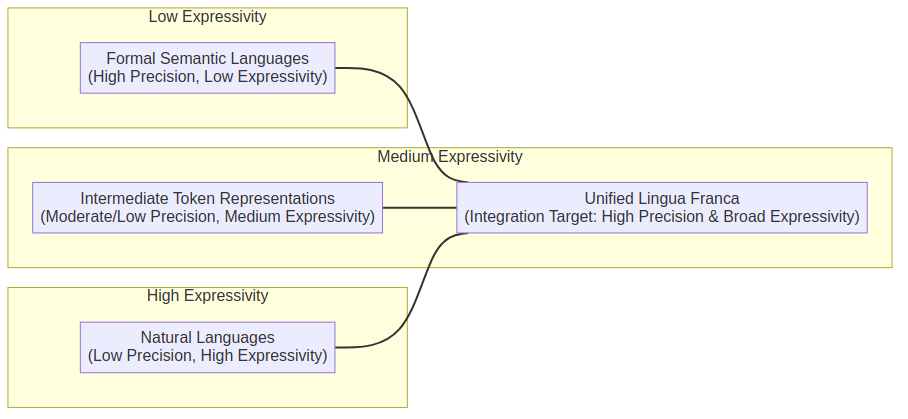
Kind-of-ok LLM generated mermaid diagram
Formal semantic languages such as RDF encoded description logics (which in most profiles has a sub first-order expressivity), are a good means of precisely describing information – supporting interpretability and interoperability of data between systems. For much data with clear-cut attributes like the address, DOB, and website of a user – these languages can capture full information.
However, the fact that these languages are constrained to a particular logical profile, (e.g. First Order Logic) means that there – by definition - is a limitation to what they can express. In contrast, natural languages such as English are highly expressive – and have no formal ruleset to describe how the language should be interpreted and executed. Instead, the only systems to date that can operate upon the full spectrum of natural language (including the human brain, LLMs and other machine learning systems) are those which have learned by example; and thus, will have contextually dependent interpretations and reactions to the language. Moreover, multilingual speakers often attest to the idea that there are gaps in the expressible concepts between different languages – thus indicating that contemporary natural language does not effectively capture of all concepts relevant to daily life – let alone all concepts that could be communicated by a human or machine. In the context of communication between LLMs, there is an emergent discussion of whether it would be appropriate to communicate using intermediate token representations rather than natural language. In theory this may improve expressivity but will nevertheless remain restricted to the conceptual model that lives within LLMs.
If we are to work towards a Web of Agents that accurately and effectively negotiate, communicate and cooperate with maximal versatility, efficiency and unambiguity (where versatility and efficiency are defined as per Section 3 of this paper) then we must work towards the design of a lingua franca for inter-system communication that encapsulates all of these different language modalities.
Moreover, we observe that the process of describing a concept in a higher-order modality, may be seen as conceptual alignment to allow that concept to be operationalised across systems in a lower-order modality. We already see this today in the way that RDF taxonomies are created – the Data Privacy Vocabulary for instance creates a taxonomy of terms defining a range of purposes for which data may be used. However, the definition of the purpose is still described using the natural language rdfs:description.
This means that whilst, for instance, an ODRL policy can be formalised using a first-order-logic calculus description with the ODRL data model and DPV terms; the implementation of a policy engine operationalising that description will still require a human (or LLM) to interpret the natural language and codify the actions the system should take when, for instance, one is permitted to use data for dpv:Marketing which is defined in natural language as “Purposes associated with conducting marketing in relation to organisation or products or services e.g. promoting, selling, and distributing”. There is also a question of what, if anything, sits between formal-logic and natural language. We are not the first to pose such a question.
I’m sure there is some interesting Thery of Mind type stuff to investigate in here if one was to start properly digging – but I am going to withhold from that until I decide if I am going to do research in this direction. Guidance note I don’t think it is going to be possible to invent much of this in a top-down manner. Would start first in a use-case driven manner.
Possible intermediary points include:
- Normalised natural language (e.g. application of strict grammar rules and/or reduction to a concise and precise language.)
- Building hybrid KG / VDB architectures and understanding the internal representation + mapping between the two views may go a long way in assisting with the creation of this intermediate representation.
Conceptual alignment between agents (including LLM, neurosymbolic, and logical-only)
Work includes evaluating how well LLM-based agents can collboratively describe and build formal conceptual models of the world in order to discuss new concepts on the fly.
Web-aware agents
In this paper we present a vision of how we can evolve from the current paradigm of Computer Using Agents (CUAs) towards Personal AI Agents reminiscent of the 2001 Semantic Web Vision Paper. In the same paper, we posit that a migration towards a Web of self-describing agents will only be possible should we make operator style agents Web-aware. What this enables is for Web Agents to more feasibly learn what the “action space” of a particular website is, and more efficiently affect operations.
Bootstrapping Web Agents
In this paper we present a vision of how we can evolve from the current paradigm of Computer Using Agents (CUAs) towards Personal AI Agents reminiscent of the 2001 Semantic Web Vision Paper.
In the same paper paper, we posit that a migration towards a Web of self-describing agents will only be possible should we first bootstrap a critical mass of such agents from existing Web Services. This is particularly important when interacting with legacy services that may not have any active maintainers. The core research questions here are:
- How does one discover the action space of a Website
- How does one describe that action space of said Website, e.g., with Semantic Web Service Descriptions In parallel, we create the opportunity to begin to develop more bespoke search engines / indexing engines for a Web of Agents. In the same way that schema.org enabled Google to effectively index information embedded in Websites - including movie schedules - and present aggregate information at the top of a search result, this work creates the possibility to create an index of what range of actions a particular platform supports.
For "operationalising the action space" - e.g. going from call to the agent interface to website interaction, we could experiment to evaluate whether we can bootstrap existing Websites into becoming agents using LLMs to generate RML style mappings + potentially playwright interactions for Websites and APIs.
Privacy Preserving Reasoning over Decentralised Ecosystems
See here.
“Belief” in semi-autonomous agents via personalised models of trust
Exploring Risk Ontologies and Legal Data Sharing Agreements for Next-Generation Data Governance
Extracting ontological models from LLMs
Ontological construction has traditionally been a time consuming, slow and expensive progress – requiring close collaboration between knowledge engineers and domain experts.
In this work package shall test the viability of using LLMs to do a first pass of ontology construction. However, the goal is to investigate whether this can be done using mind mapping techniques rather than prompt engineering.
Symbolic conceptual memory modules for Deep Learning models
For both:
- Interpretability purposes
- Semantic committment purposes
Hybrid KG & Vector Database architectures
The core idea here is to build a DB with both a VDB and a KG view. Bergi has already done some work on this topic here and here.
There is further related work here.
The first piece of work I would be interested in is a formal specification for calculating points in vector space of knowledge graph concepts.
Probabilistic RDF 1.2
Following on from the above topic we need to define precise semantics for describing probabilities and performing inference with said probabilities in RDF/SPARQL 1.2. In particular, see Bergi's article on tackling uncertainty.
This may take the form of a prov-o(?) extension to enable the expression of concepts such as how sure a given entity is that a claim is true.
Knowledge Graph Memory For LLM-Based Agents
There is emerging work, such as this on LLM memory, which build memory such as SSD access directly into the LLM architecture - rather than needing to perform this via RAG into the LLM prompt.
The goal here is to build specialised architectures for access to graph-structured data.
Open Research Dashboard
As a way towards having a fully online collaborative environment – encourage researchers to discuss ideas on a topic on a platform that uses Solid and ActivityPub, and have either humans or machines label the topics for each idea.
Then allow one to browse / view who is working on what, as well as their latest progress – e.g. on GH.
Search interfaces to discover semantically described data and datasets
This includes:
- A good portal which supports the discovery of authoritative entity identifiers such as WebIds based on a natural language query - this could be for name "Jesse" or a rough description "Australian guy working on AI and Solid."
- A good portal to discover semantically described datasets such as those described using Croissant or DProd.
Operationalizable guidelines on how to comply with regulatory requirements as a host of decentralized infrastructure
In particular - today - as a host of:
- Decentralised social media - such as Mastodon, or
- Decentralised storage such as a Solid Pod provider
and in the future as a host of e.g. decentralised AI services.
Industry consortia do the work of creating such operationaliseable guidelines within their own domains. For instance, the financial indusry has created the Cloud Data Management Controls (CDMC) which provides a framework for operationalising GDPR when managing financial data in cloud services.
Some writing on the topic specifically in terms of Solid is here.
Machine-readable definition of RDF syntaxes (probably boring topic for most people)
Not just ANTLR grammar definitions for syntax for lexers; also prescribing how this maps to triples for parsers.
Starting point here
Malleable Software for Solid (read: RDF data structures and Shapes)
Semantic commitments all the way down
Work towards have transactions on the Web semantically described commitments
Say goodbye to the cloud and hello to the dataspace
Don't write apps and code agains servers - write them against data instead.
Using LLMs to create a densely linked Web
Before we move to a fully fledge web-of-concepts, I believe LLMs have a strong role to play in densely linking the Web. That is, helping us relate all of the knowledge that has been written about so that it is much easier to discover all of the existing research on a given topic - going beyond existing work such as tools:
- That link papers based on human annotated links, such as citations of papers that people have discovered that are related, and
- OpenAI researcher agents which are able to crawl the web and identify papers which are about a particular topic
Model response (may be applicable to Web Agents WG)
One feature that has supported the Web to scale is having public and cacheable resources. I recommend standardising an HTTP interface that can be used to GET responses from LLMs in a way that allows these responses to be stored in DNS caches.
For responses that require payment - e.g. because of the size of the model needed to answer the query - then there should be a redirect flow to "unlock" the link and then keep the response cached and public. See extension on this thought in the following topic.
Standard for making per-request payments to LLM providers (may be applicable to Web Agents WG)
So that services relying on those LLMs need to implement the standard rather than create custom flows and deals for each LLM service.
Extending this - directly delegating authorization of payments to a user account - so that they can:
- Make use of ongoing subscriptions on existing platforms
- Further, delegate the cost directly to their organizations when using services for work
- Have a single platform that they connect their bank accounts to and set controls for "LLM usage"
One Identify for agentic platforms (may be applicable to Web Agents WG)
Largely to achieve the above item
LLM metadata for discovery (may be applicable to Web Agents WG)
Presumably products that use LLMs - such as cursor - need to manually curate the list of LLMs that they are using in their product. As the number of LLMs that are available proliferates, it may be better for LLMs to provide a .well-known description to identify the capabilities, cost and usage mechansim.
Agent Chat Rooms (may be applicable to Web Agents WG)
To enable, for instance, groups of personal agents to organize travel plans for a party of 5 people, or distributed tooling agents to negotiate with each other.
In the medium term I would think that these are more somethign like "concept whiteboards" - but agent chat rooms are a good place to start.
Standardize authentication for LLMs to access private resource
Intersects both with goals of MCP, Solid and protocols like OIDC4VP
Standard sharing of re-usable context data
Standardise Solid as the way of having agents request and use contextual data. With both:
- Access Controls (including which services can access it)
- Usage controls (including which services results can be forwarded to, and whether the data can be used for monetization)
More things to standardise in the LWS-WG
Other Web Agents Group topics could include:
- Standardize search interface to support and look up of publically available vectorised data
- Taxonomise common services of LLM providers (e.g. embeddings endpoint, what modalities does a provider support etc.)
- Describing which models you have deployed where. In particular to allow the discovery of multiple deployments of opensource models; and to allow agentic workflows to define "this model must be used here" but then automatically do things like work out if it is deployed locally, and if not find a trusted remote deployment that can be used.
This is a living document